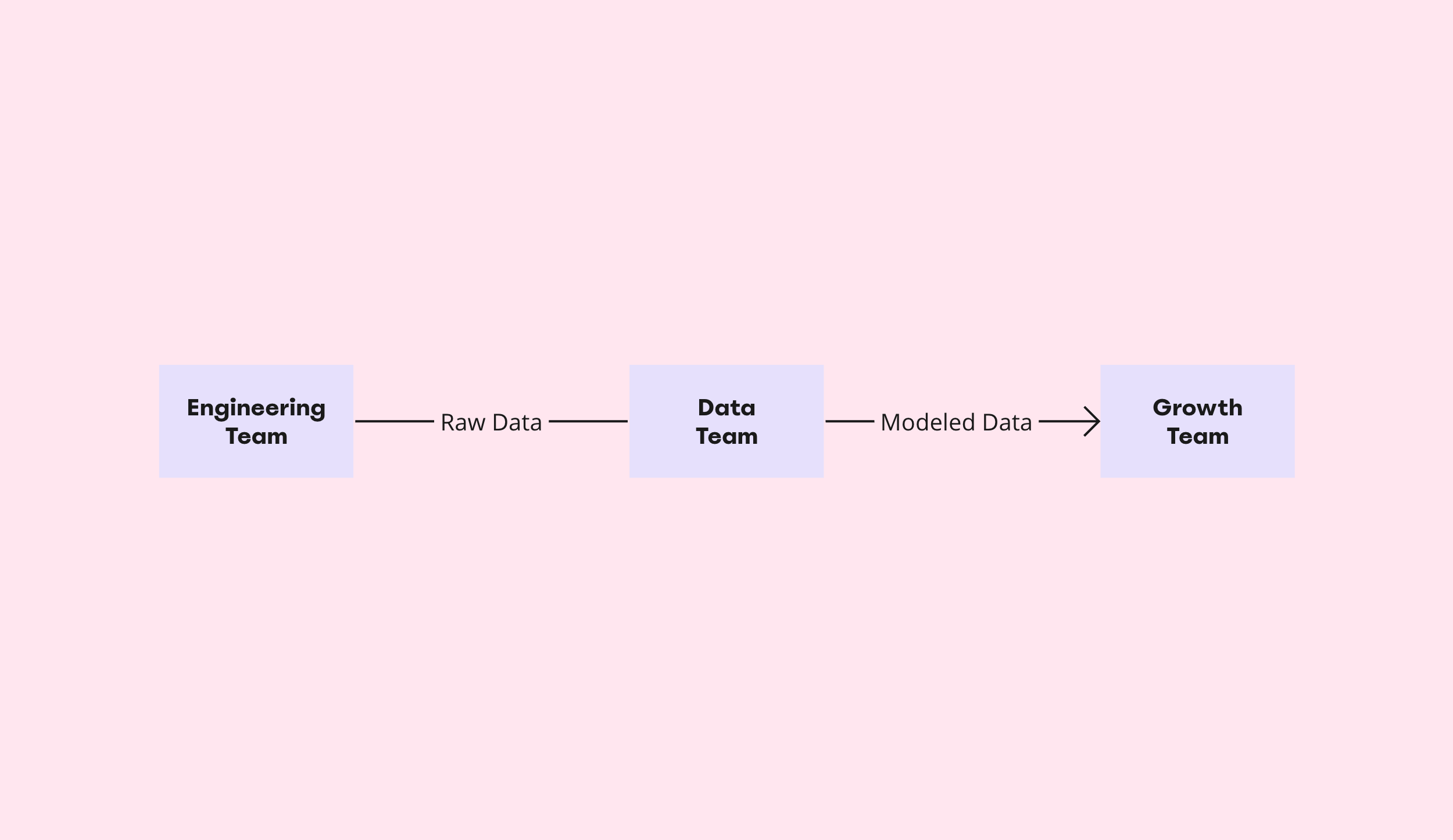
I don’t know what got us here but today, it’s a common practice for teams to collect all the data they can from all possible sources and store it all in a centralized database – even when there is no context or predefined purpose.
Contextless data collection has become somewhat of an obsession, and the rationale behind this obsession is that data becomes more accessible for teams when stored in one place (typically a cloud data warehouse, data lake, data lakehouse, or whatever comes next).
However, even though modern data tools have made it cheaper and faster for teams to collect, store, and access large amounts of data, we have to ask these questions:
- What’s the point in making data accessible without a predefined purpose and a measurable outcome?
- If there’s no experiment to run, decision to make, or outcome to measure, why should the data be collected in the first place?
After all, data collection, like any other activity, requires talented individuals to expend their energy and organizations to spend money.
We have to keep in mind that as soon as the collection process is set in motion and data begins to land in the centralized storage unit in the cloud, storage costs begin to accrue. On top of that, querying the data to create a report or to move a dataset to a downstream system is an additional cost.
Lastly and most importantly, the larger the amount of data, the longer it takes to run a query successfully, which in turn, costs more money.
Let’s look at an example:
X and Y offer competing products and both maintain a report that fetches the latest data every morning (a query being run on a schedule). The CEO of X believes in collecting all the data, irrespective of whether it’s needed for the daily report or not. On the contrary, the CEO of Y thinks it’s better to collect only the data needed for the daily report.
X is obviously paying more for storage, but that’s not it. Every time their respective queries run, X pays more than Y for compute as well because X’s query takes longer to run as it has to process more data.
This is a simplified example but you can imagine the impact when this scenario is multiplied by the number of different queries that are executed every day at large organizations. Irrespective of the outcomes, they end up spending a lot on their cloud bills (and then spend more figuring out how to reduce those bills). Moreover, more data not only increases direct expenditure but also increases the element of risk in the event of a privacy audit (or data breach).
But for a minute, even if we put cost and risk aside, the practice of contextless collection hinders growth teams from getting involved in the data collection process which further prevents them from understanding what data is needed to answer their questions – a prerequisite for folks who are hungry to drive growth using data.
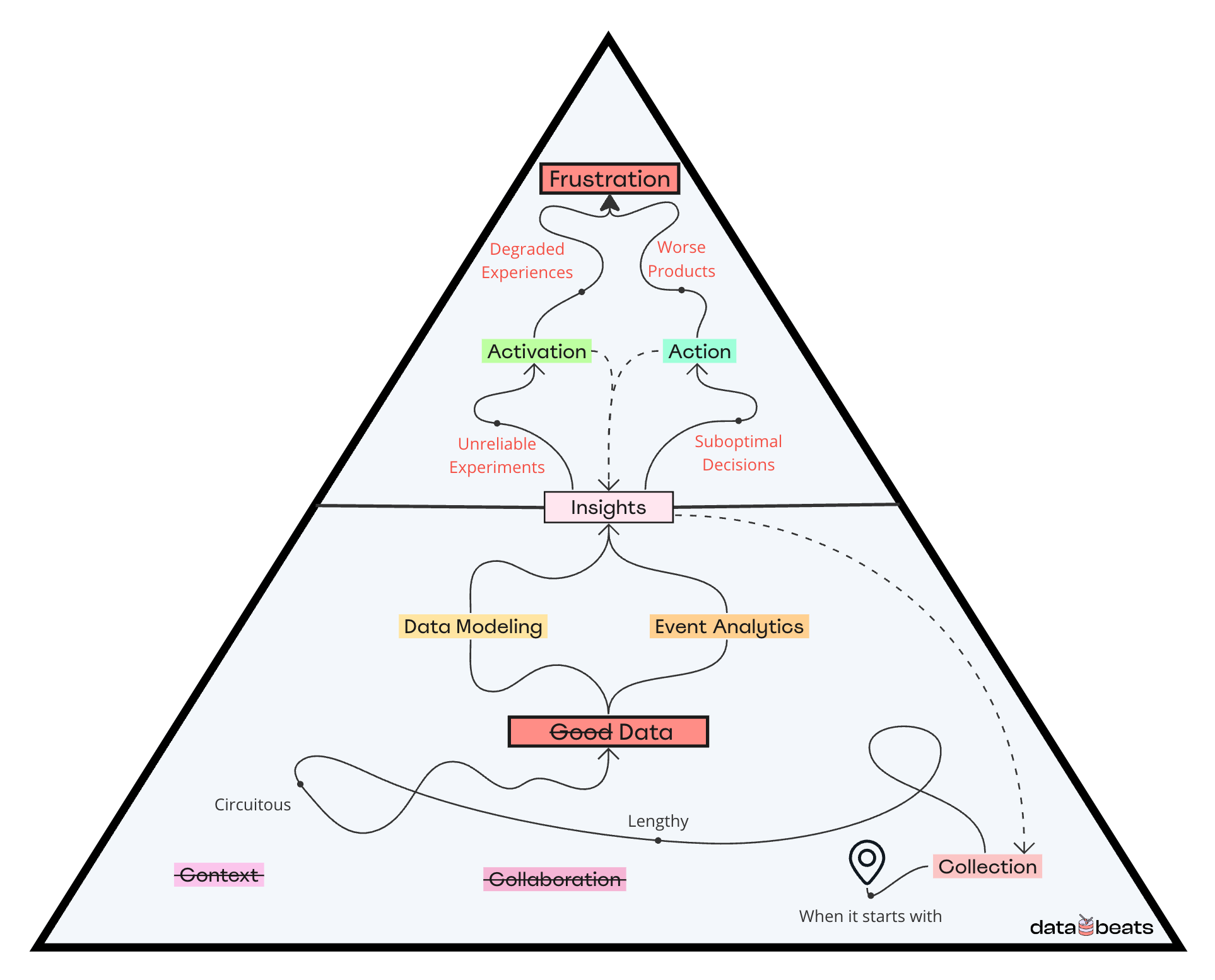
As depicted in the figure above, contextless data collection is the antithesis of the GDG model – it appears to be faster but sooner or later, the process becomes lengthy and circuitous, and adversely impacts everything that follows.
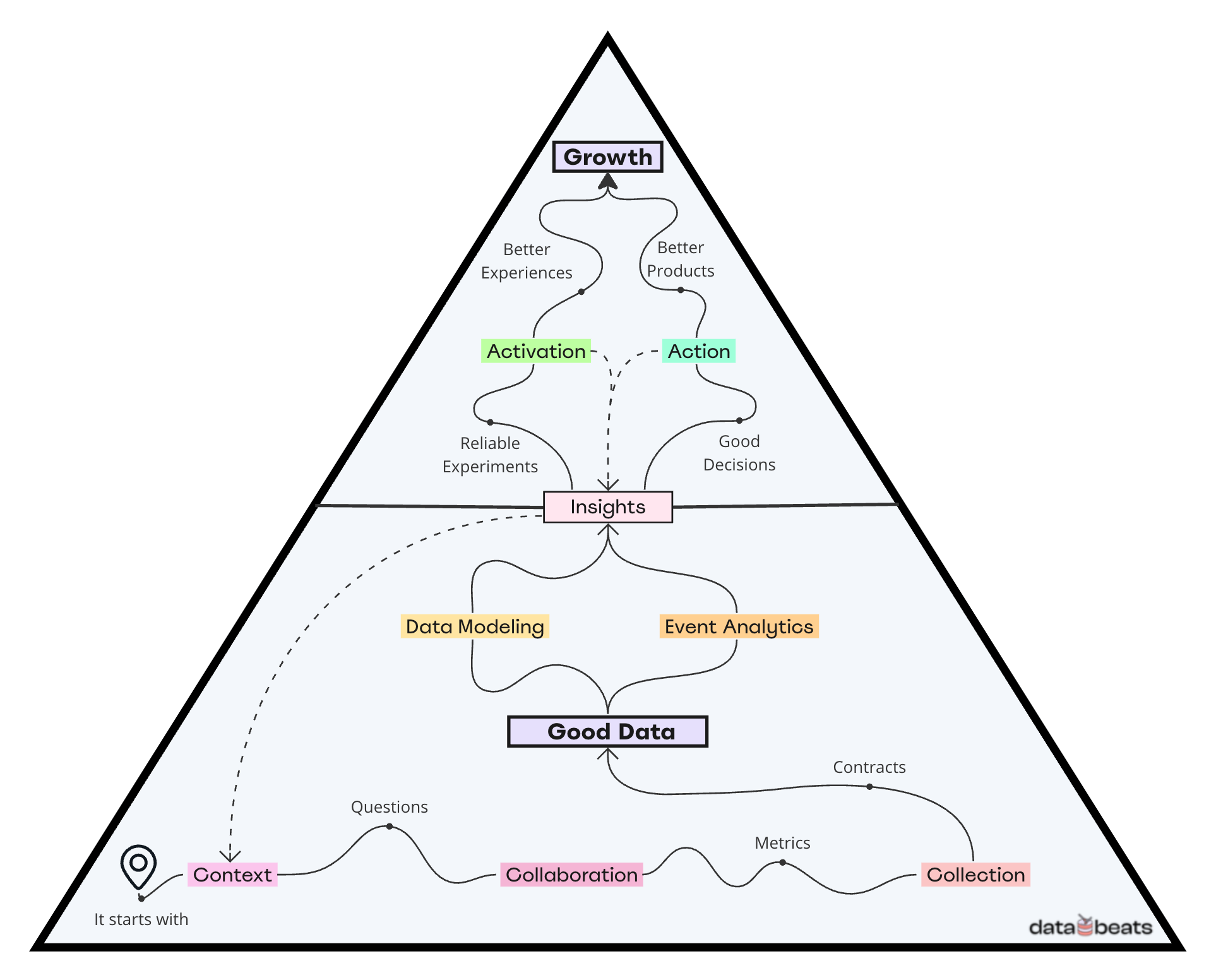
On the contrary, when there’s context, questions come up leading to collaboration between teams. As a result, teams are also able to come up with relevant metrics before collection is initiated, leading to a robust data foundation (Good Data).
Pause to ponder 🤔
Based on what you’ve read so far, take a few minutes to think about these popular narratives:
- Why is it considered good practice to collect and store all the data in a centralized location, especially when it’s evident that doing so leads to more cost and higher risk for orgs?
- Is it enough to make data accessible to teams or do orgs need to ensure that any data that’s made accessible is also put to use to drive growth?
The outcome of contextless data collection: A scenario
Jim decides to run a survey after reading a blog post titled “10 ideas to grow your product” which listed “run a survey to ask users for feedback” (of course it did).
So Jim goes ahead and creates a survey using a product feedback template. Jim says to himself, “Once I have some data flowing in, I’m sure I can figure out many ways to put the data to use.”
Since Jim hasn’t thought through what exactly he intends to do with the data, he has no context to come up with the right questions or for instance, carefully evaluate the values of the items in the dropdown field or whether he should change that to a multi-select field or whether or not he should provide an “other” option.
After a few weeks of running the survey and feeling good about all the juicy data, Jim shared the survey results with his boss, who asked him to create a report that breaks down the user data by industry and role. Jim was already collecting those data points in the survey; however, after inspecting closely, he realizes that some of the key industries Jim’s company served are missing in the dropdown, Additionally, the field capturing the user role happens to be a text field and as a result, there are a ton of different values for the role field instead of predefined ones that are relevant to the business.
Now Jim is in a dilemma: Should he fix the survey so that going forward, the data helps answer questions more accurately, or should he leave the survey unchanged and report on whatever data is available?
While fixing the survey makes complete sense, it will result in two different data sets, and to combine them, Jim will need to wrangle the data or get the data team’s help to run the results through a bunch of transformations.
In retrospect, had Jim applied rigor to the process of designing the survey, he would have included his burning questions and made sure that he used the right data type2 for each question and populated the dropdown field with the right options, resulting in something more usable and scalable.
This hypothetical scenario applies to every type of data that can be collected from any type of source.
For example, lack of context at the time of instrumenting events leads to redundancy, events missing key properties, or events instrumented client-side when they should have been instrumented server-side. These prevalent errors lead to a lack of trust in the data by the growth team, frustration for the data team, and a massive resource drain for the organization.
Conduct this exercise 🏋️
Pull up a recent survey or report and think about the following:
- Does the data help answer your burning questions?
- Did you end up collecting data you’re not sure how to use?
- In terms of data collection, what would you do differently if you could start over?
If you answered “yes”, “no”, and “nothing” respectively, congratulations – it’s likely a result of proper context at the time of collection.
If not, well, you know what to do the next time you have a burning question or decide to run a survey.



.svg)
.svg)

.svg)