The Why
At early or even mid-stage companies, it’s not uncommon for software engineers, rather than data engineers, to build and maintain data pipelines. At Integromat, the first data person – a data generalist – was hired only after we started hitting the limits of what was possible with the existing data infrastructure. We needed someone to take over the maintenance of the data pipelines as Dom and Pete – the engineers who had set them up – had to focus on their software engineering responsibilities.
The core Integromat platform was rearchitected to make the product more scalable, performant, and compliant, and was eventually launched as Make. As you can imagine, it was a massive undertaking that could potentially break all existing data pipelines, directly impacting the downstream tools that relied on the events and properties that originated in the web app.
The above scenario is a rare example of how product changes impact data workflows (I’m not aware of the actual impact since I had moved on from Integromat before the launch of Make).
In reality though, even a tiny change by the engineering team in a product feature, if unaccounted for by the data team, can lead to inconsistent data, or a potential loss of the data pertaining to that feature. Even if the feature isn’t instrumented (its usage isn’t tracked as events), the usage data logged in the production database is impacted.
Let’s look at a scenario:
Linda, a data engineer, has scheduled an ETL job that runs every morning and replicates the data from the production database into an analytical database (a data warehouse) to power an executive report that uses data from the user onboarding survey, which was part of the account creation process.
However, Sid, the software engineer who maintains the user authentication service pushed an update (by merging a pull request he had discussed with his manager) which made the mandatory fields in the onboarding survey optional, making the daily report suddenly look very different.
An executive noticed something was amiss and brought it up in an emergency meeting. As a result, Linda, who was hoping to do some meaningful work, found herself scrambling all day to figure out what caused the data loss, only to find out the next day what caused the issue. Sid, on the other hand, had no idea that performing a simple task he was assigned would cause such a fire drill.
This scenario is rather simple but should help you understand the impact of Engineering workflows on Data workflows.
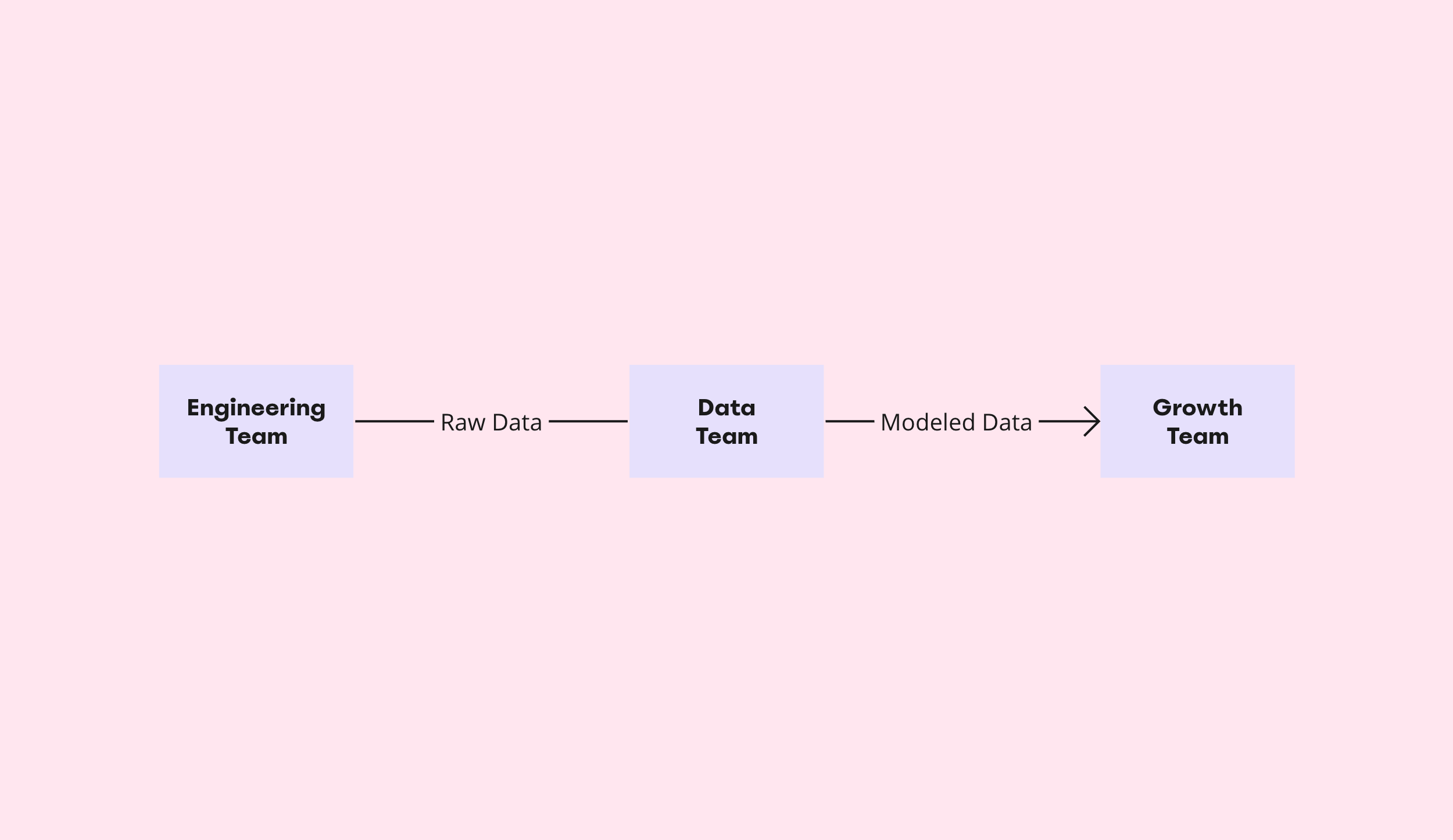
The figure below illustrates the dependencies between raw data (produced by Engineering), modeled data (produced by Data), and the reports consumed and experiments conducted by Growth.

The impact is often inconspicuous and the outcome is usually a fire drill. Therefore, there needs to be a system in place to ensure that any feature change made by Engineering – no matter how seemingly insignificant the change – is communicated to Data before that change is pushed to production. Doing so will enable the data team to account for the changes, make necessary adjustments to the data pipelines, and thereby prevent downstream reports and experiments from being impacted.
Sounds obvious, doesn’t it?
Most people when presented with the notion that the data team must be kept in the loop regarding product changes by the engineering team would assume that this happens already. I certainly didn’t feel the need to spell this out when working with Dom and Pete (the engineers I collaborated at Integromat) and I absolutely took it for granted that they will consider the downstream impact of any change they make upstream. However, in reality, that’s not the case – crazy but true!
Thankfully, some people in data (who must have experienced the disastrous impact of broken pipelines due to upstream changes) became vocal about this problem which led to the emergence of data contracts.
The What
A data contract is a new construct that advocates the need for contracts (or agreements) between data producers (the engineering team) and data consumers (the data team) to ensure, amongst other things, that before an engineering team member pushes an update to the production environment, the data team should be informed.
A workflow like this enables the data team to assess the potential impact of the upcoming change on the existing data models and pipelines (that may or may not be impacted by the update), and if needed, make adjustments before the impact reaches downstream.
There’s a lot more to data contracts, and depending on the level of sophistication teams seek, a contract can include other details for a data point such as its data type, its intended use, where the data will be stored for how long, and so on. However, rather than going into the technicalities, my goal is to help you understand the notion of data contracts and how they help build a robust data foundation (Good Data).
In essence, data contracts help maintain a high bar for data quality, ensuring that the data that reaches analytics and activation tools is reliable, consistent, and as expected – it adheres to the predefined schema and conforms to the validation rules.
If you’re wondering what a contract looks like and how it’s enforced, there are two things about data contracts to keep in mind:
- A data contract isn’t a document that is signed by two parties and enforced by law; a data contract is a workflow (built atop existing workflows of engineering and data teams) that can be implemented in many different ways.
- And more importantly, while tools are being built to make it easier for organizations to adopt this workflow, on a fundamental level, the problem at hand can only be solved by setting up better processes and facilitating better communication between teams.
An example: Notion’s hypothetical invitation flow
To conclude this post, let me share a relatable example that illustrates the usefulness of data contracts.
Productivity tools like Notion allow workspace owners to add new members to their workspace manually by sending invites via email – a pretty standard action that can be tracked as an event for analytics or activation purposes. For instance, the growth team might want to track the number of invites sent and trigger a reminder email if an invite is not accepted within a certain timeframe. Or the product team might want to trigger an in-app message as soon as the first invite is sent, asking the workspace owner if they’d like to test a new collaboration feature.
Let’s assume that these two use cases have been implemented at Notion, and Theo, a (hypothetical) data engineer at Notion, maintains a pipeline that tracks workspace invites and syncs data to a couple of downstream tools.
Now, since multi-user collaboration makes tools like Notion more valuable for teams, the engineering team decided to make it easier to add new members to a workspace and therefore, shipped two new ways to do that – by generating an invite link (and sharing it manually) and to make it even more seamless, by connecting a Slack workspace.
However, nobody from Engineering informed Theo about this update. As a result, the new features were not instrumented and the usage data didn’t reach the downstream tools being used by Product and Growth.
In this scenario, the existing data pipeline is unaffected. However, now that there are easier ways to send invites (which go unaccounted for), the number of invites tracked has gone down significantly (only email invites are being tracked), sending Product and Growth, and ultimately Theo in a state of flurry to figure out why, all of a sudden, are workspace owners not sending enough invites.
Had a data contract been in place, Theo would have been informed about the updates beforehand, would have updated the pipeline that tracks workspace invites, and this fire drill could have been avoided.
In this example, the issue is relatively simple but is difficult to diagnose nonetheless. In reality, a typical engineering team regularly pushes changes and improvements, each of which has the potential to have an inconspicuous impact on downstream reports and experiments.
Moreover, inconsistencies or breakages caused due to upstream changes are hard to diagnose even in the presence of data monitoring solutions because there lacks a connective thread between the workflows of Engineering, Data, and Growth – all of which, are in fact, connected.
Ask the data team 🙋
If you don’t already have answers to these questions, find out by asking a data or engineering counterpart:
- Is there documentation describing what data is being collected from our app? What’s the process to collect new events?
- Where do we store the data? How can I explore it?
- What are the destinations in our stack? What’s the process to add a new one?
While it might seem so, this exercise is anything but easy. But if somehow it turns out to be easy for you, congratulations, you’re one of the lucky ones!



.svg)
.svg)

.svg)